


 DragonJAR
DragonJAR 8.8 Chile
8.8 Chile Ekoparty
Ekoparty e-Hack MX
e-Hack MX  AREA 51
AREA 51  Comunidad Dojo Panamá
Comunidad Dojo Panamá  ARPAHE SOLUTIONS
ARPAHE SOLUTIONS 
"Are You Talkin' ta me?" Voice Analysis with Machine Learning
En la primera parte de este artículo pudimos ver el planteamiento de la investigación, que dividíamos en primero analizar quién, cuándo y para que ha utilizado tu SmartSpeaker, en segundo lugar poder hacer un doxing de una persona "desconocida" utilizando tu SmartSpeaker, y tercera, en ver si es posible, o con qué cantidad de audios se puede, clonar un voz de forma suficiente como para afectarle en su vida personal.

En la parte de hoy, vamos a ver la parte de cómo analizar la voz con técnicas de Machine Learning, para poder hacerlo de manera automatizada en un entorno de búsqueda de objetivos en un Data Lake de audios.
 |
| Figura 12: Libro de Machine Learning aplicado a Ciberseguridad de Carmen Torrano, Fran Ramírez, Paloma Recuero, José Torres y Santiago Hernández. |
Para comenzar la investigación, lo primero que sabemos, viendo el Dashboard de la primera parte, son tres cosas fundamentales, a saber:
- Qué ha dicho: Ya que tenemos las transcripciones de los comandos.
- Dónde lo ha dicho: Porque sabemos dónde tenemos nuestro SmartSpeaker.
- A qué hora lo ha dicho: Porque tenemos los horarios de los comandos.
Esta información, en un análisis forense es muy útil, y es conveniente tener todo bien documentado, y organizado en nuestros informes, para comenzar la investigación.

Figura 13: Cadenas de texto de los comandos de la persona "Unknown"
De todos estos comandos que tenéis a continuación, y que han sido por un "Unknown", nosotros vamos a centrarnos en uno de ellos para hacer la investigación.
Voice Analysis with Machine Learning
Para comenzar el proceso, nosotros vamos a contar con un audio de alguien que ha estado utilizando nuestro SmartSpeaker sin nuestro consentimiento o conocimiento, y vamos a intentar descubrir al máximo de él. Este es el audio que usaremos como objetivo.
Figura 14: Fichero de Audio de persona "Unknown"
Lo primero, con el objeto de poder reducir la búsqueda de posibles objetivos, y pensando en que vamos a utilizar este fichero como base de comparación contra un Big Data de audios, del que hablaremos después, vamos a analizar detalles sencillos, como el género, la edad o el sentimiento que se extrae de la voz.
Espectrogramas de Audio
Para estimar cuál puede ser la edad de la persona que está hablando en un fichero de audio, vamos a utilizar la idea del trabajo de Michael Notter que se basa en generar un espectograma de las caracteristicas del habla de una persona en un fichero de audio.

Figura 15: Features del habla en un audio y su relación
El objetivo es extraer todas las características del habla, que van desde el número de palabras por unidad de tiempo, la distancia entre palabras, la variación de frecuencias, etcétera, y generar una tabla de relación entre ellas.

Figura 16: Espectogramas medios de hombre y mujer del dataset de entrenamietno
Age Estimation
A partir de ese momento, con un dataset de voces de hombres y voces de mujeres etiquetado se hace un algoritmo de clasificación con Machine Learning de los espectrogramas generados de cada fichero de audio que queramos analizar, usando en este caso las librerías de scikit, librosa, numpy y scipy entre otras.

Figura 17: Modelo de predicción de edad de un audio (en décadas)
El resultado, una vez entrenado el modelo es que tenemos un script en Python que se puede utilizar para automatizar la tarea de generar metadatos de cualquier grabación que exista. Muy útil para los equipos forenses que quieran analizar grabaciones masivas.
Como podemos ver, estima que es la voz de una persona de entre 40 o 50 años, ya que el algoritmo de clasificación no se ha ajustado mucho más. Es una aproximación que, además, en este ejemplo concreto concuerda con la realidad.
Gender Prediction
Este modelo es un entrenamiento propio, basado en el estudio anterior. Utilizando los mismos espectogramas entrenamos un modelo de Machine Learning usando Tensorflow, Keras, Scipy y Librosa entre otros para generar un algoritmo de clasificación entrenado con un dataset de voces de hombres y mujeres etiquetado.
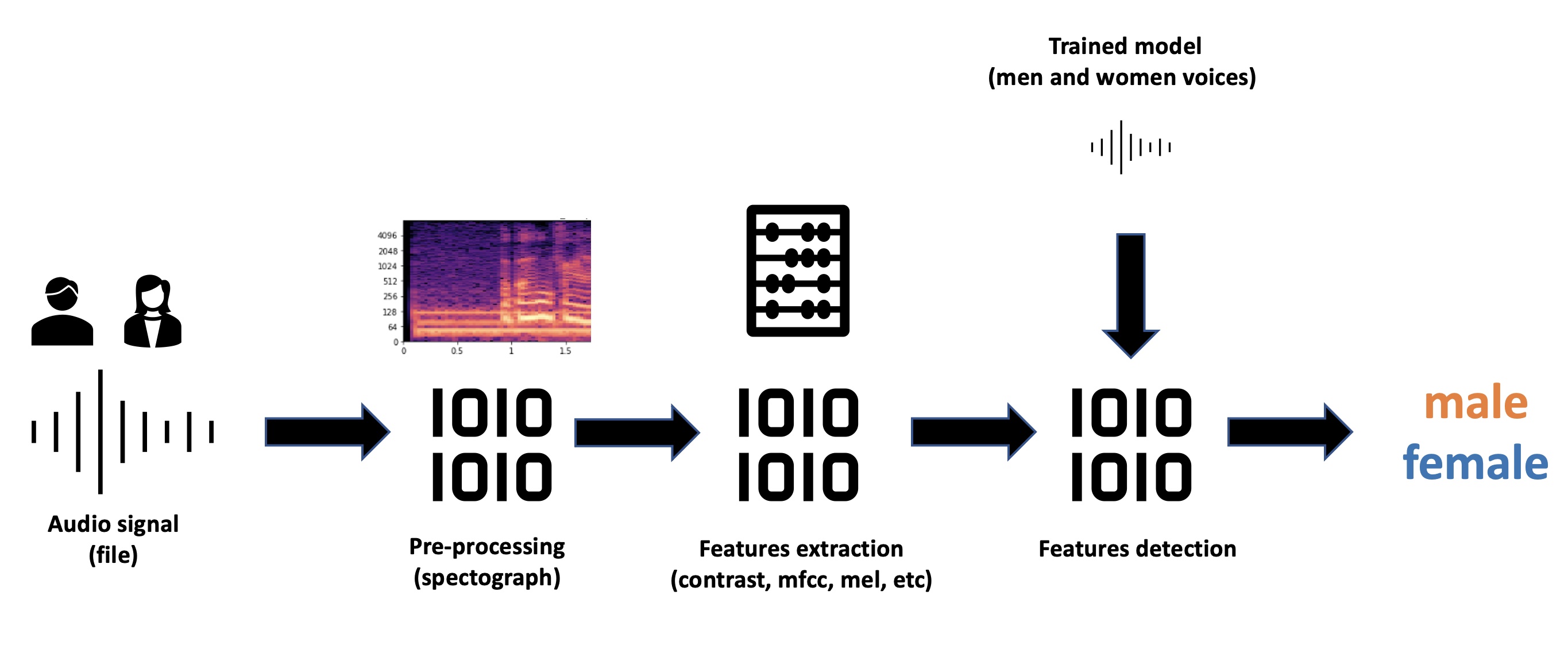
Figura 19: Algoritmo de Gender Recognition
El resultado, de nuevo, es un script en Python que puedes utilizar para reconocer el género automáticamente de cada uno de los ficheros de audio en una muestra. En este ejemplo, que lo hemos escuchado, el resultado es bastante sencillo.
Figura 20: Gender Recognition con con Machine Learning
Al final, el objetivo es poder tener un script que pueda procesar y ayudar a lo localizar personas en audios de una manera rápida, y poder clasificar por género ayuda mucho en la reducción del tiempo de búsqueda.
Sentiment Analysis
De igual manera que la edad y el género, queríamos tener un algoritmo de análisis de sentimiento. Se trata de poder clasificar los audios, las emociones de las personas, y al mismo tiempo poder usarlo como forma de correlación automática en entornos de DeepFakes, como veremos un poco más adelante.

Figura 21: Modelo de Sentiment Analysis
El modelo de Machine Learning entrenado se basa también en los espectogramas, con un entrenamiento de voces de personas catalogadas en sólo tres categorías, Sad, Neutral y Happy. El resultado con nuestro ejemplo es el siguiente.
Figura 22: Sentiment con con Machine Learning
Con tres sencillos algoritmos de Machine Learning podemos añadir tres datos más a la investigación de cualquier audio, como son el género, la edad y el sentimiento que muestra en el audio. Por supuesto, son solo ejemplos que se pueden ir perfeccionando - y que nosotros seguiremos perfeccionando - porque pueden ser de utilidad en análisis en tiempo real de DeepFakes, como veremos un poco más adelante.
*********************************************************************************************
*********************************************************************************************
¡Saludos Malignos!
Autor: Chema Alonso (Contactar con Chema Alonso)
















No hay comentarios:
Publicar un comentario